Amazon Redshift를 사용해야 하는 이유는 무엇인가요?
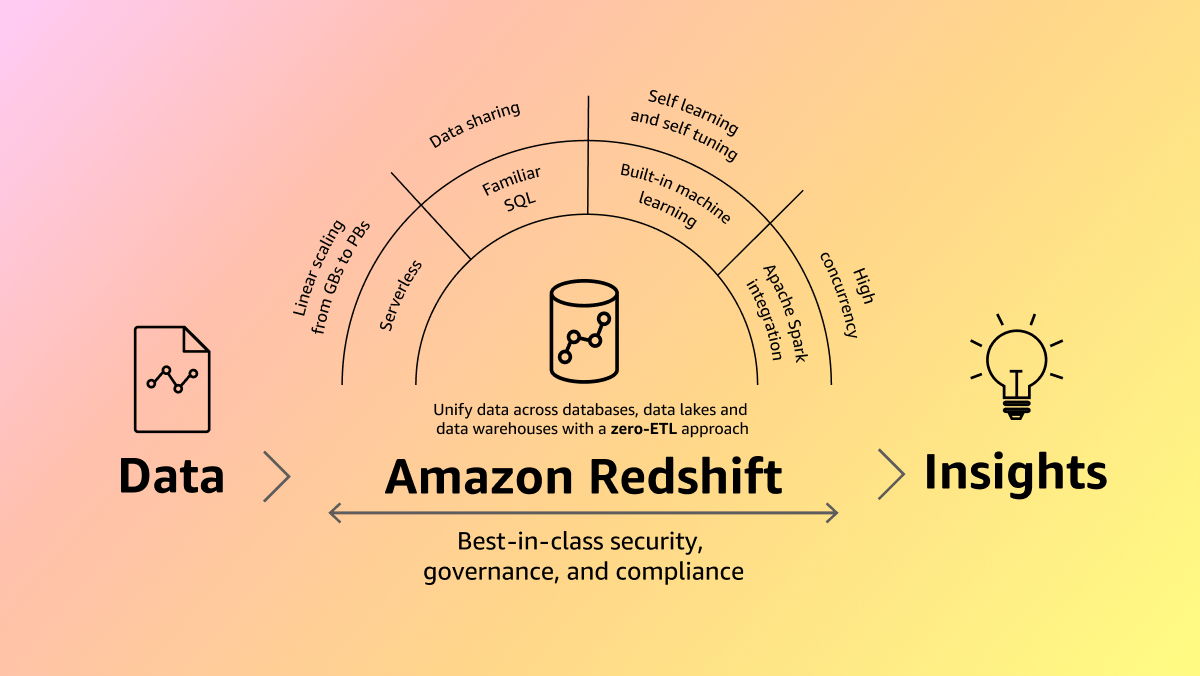
수만 명의 고객이 대규모 최신 데이터 분석에 Amazon Redshift를 사용하여 다른 클라우드 데이터 웨어하우스보다 최대 3배 더 나은 가격 대비 성능과 7배 더 많은 처리량을 확보하고 있습니다. Amazon Redshift는 Amazon SageMaker Lakehouse와 원활하게 통합되므로 Amazon Redshift 데이터 웨어하우스 및 Amazon Simple Storage Service(Amazon S3) 데이터 레이크 전반의 통합 데이터에 대한 강력한 SQL 분석 기능을 사용할 수 있습니다. 복잡한 데이터 파이프라인을 구축하지 않고도 스트리밍 서비스, 운영 데이터베이스, 서드 파티 엔터프라이즈 애플리케이션의 데이터를 연결하는 Amazon Redshift 제로 ETL 통합으로 실시간에 가까운 분석을 통해 의사 결정을 가속화할 수 있습니다. Amazon Redshift Serverless를 사용하면 분석을 손쉽게 확장할 수 있으므로 인프라 관리에 대한 부담 없이 페타바이트 규모의 데이터를 분석할 수 있습니다. 자연어를 통해 SQL 작성을 간소화하는 Amazon Q in Amazon Redshift를 사용하여 팀의 생산성을 향상시킬 수 있습니다. Amazon Redshift를 Amazon Bedrock의 생성형 AI 어시스턴트를 위한 구조화된 지식 기반으로 사용하여 데이터의 가치를 극대화하면 애플리케이션에서 더 관련성 있고 정확한 출력을 얻을 수 있습니다.
이점
작동 방식
사용 사례
Amazon Redshift Serverless
데이터 웨어하우스를 프로비저닝 및 관리하지 않고도 몇 초 만에 손쉽게 분석을 실행하고 확장할 수 있습니다.
오늘 원하는 내용을 찾으셨나요?
페이지의 콘텐츠 품질을 개선할 수 있도록 피드백을 보내 주세요.