Basi di conoscenza di Amazon Bedrock
Con le basi di conoscenza Amazon Bedrock puoi fornire ad agenti e modelli di fondazione (FM) informazioni contestuali estratte dalle origini dati private della tua azienda per fornire risposte più pertinenti, accurate e personalizzate
Supporto completamente gestito per il flusso di lavoro RAG
Per dotare i modelli di fondazione (FM) di informazioni aggiornate e proprietarie, le organizzazioni utilizzano Retrieval Augmented Generation (RAG), una tecnica che recupera dati dalle origini dati aziendali e arricchisce il prompt per fornire risposte più pertinenti e accurate. Amazon Bedrock Knowledge Bases è una funzionalità completamente gestita con gestione dei contenuti delle sessioni e attribuzione delle origini integrate che consente di implementare l'intero flusso di lavoro RAG, dall'importazione al recupero fino all'arricchimento dei prompt, senza dover sviluppare integrazioni personalizzate per le origini dati né gestire i flussi di dati. Inoltre, hai la possibilità di porre domande e riepilogare i dati da un singolo documento senza configurare un database vettoriale. Se i tuoi dati contengono origini strutturate, le Knowledge Base di Amazon Bedrock forniscono un linguaggio naturale gestito integrato per il linguaggio SQL (Structured Query Language) per generare un comando di query e recuperare i dati senza la necessità di spostarli altrove.

Collega FM e agenti alle origini dati in modo sicuro
Se disponi di origini dati non strutturate, le Knowledge Base di Amazon Bedrock recuperano automaticamente i dati da fonti come Amazon Simple Storage Service (Amazon S3), Confluence (anteprima), Salesforce (anteprima), SharePoint (anteprima) o Web Crawler (anteprima). Inoltre, ricevi anche l'acquisizione programmatica di documenti per consentire ai clienti di acquisire dati in streaming o dati da origini non supportate. Una volta importato il contenuto, le Knowledge Base di Amazon Bedrock lo suddividono in blocchi di testo, convertono il testo in embedding e li archiviano nel database vettoriale. Puoi scegliere tra diversi archivi vettoriali supportati, tra cui Amazon Aurora, Amazon OpenSearch serverless, Analisi Amazon Neptune, MongoDB, Pinecone e Redis Enterprise Cloud. Puoi anche scegliere di connetterti a un indice di ricerca ibrido di Amazon Kendra per il recupero gestito.
Utilizzando le Knowledge Base di Amazon Bedrock, puoi anche connetterti ai tuoi archivi di dati strutturati per generare risposte fondate. Questo può essere particolarmente utile quando si dispone di materiale di origine come dettagli transazionali archiviati in data warehouse e datalake. Le Knowledge Base di Amazon Bedrock passano da linguaggio naturale a SQL per convertire le query in comandi SQL ed eseguirli per recuperare i dati, senza doverli spostare dall'origine dati primaria.

Personalizza Amazon Bedrock Knowledge Bases per fornire risposte accurate durante il runtime
Con le Knowledge Base di Amazon Bedrock come soluzione RAG completamente gestita, hai la flessibilità di personalizzare e migliorare la precisione del recupero. Per le origini dati non strutturate contenenti dati multimodali come immagini e documenti visivamente ricchi con layout complessi (ad es. documenti contenenti tabelle, figure, grafici e diagrammi), è possibile configurare le Knowledge Base di Bedrock per analizzare ed estrarre informazioni significative. Puoi scegliere come parser Bedrock Data Automation o modelli di fondazione. Ciò consente l'elaborazione continua di dati multimodali complessi, permettendo di creare applicazioni di IA generativa altamente accurate.
Le Knowledge Base di Amazon Bedrock offrono una varietà di opzioni avanzate di suddivisione dei dati, tra cui suddivisione semantica, gerarchica e a dimensione fissa. Per un controllo totale, i clienti possono scrivere il proprio codice in sezioni come una funzione Lambda e persino utilizzare componenti standard da framework come LangChain e LlamaIndex. Se scegli l’Analisi Amazon Neptune come archivio vettoriale, la Knowledge Base di Amazon Bedrock crea automaticamente embedding e grafici che collegano i contenuti correlati tra le tue origini dati. Le Knowledge Base di Bedrock sfruttano queste relazioni di contenuto con GraphRAG per migliorare la precisione del recupero, rendendo possibili risposte più complete, pertinenti e spiegabili agli utenti finali.

Recupera i dati e migliora i prompt
Utilizzando l'API Retrieve, puoi recuperare risultati pertinenti per una query utente dalle knowledge base, inclusi elementi visivi come immagini, diagrammi, grafici e tabelle o dati strutturati dai database, ove pertinente. L'API RetrieveAndGenerate si spinge anche oltre e utilizza direttamente i risultati recuperati per migliorare il prompt FM e restituire la risposta. È anche possibile aggiungere Amazon Bedrock Knowledge Bases ad Amazon Bedrock Agents per offrire agli agenti informazioni contestuali. Puoi anche scegliere di fornire filtri o utilizzare FM per generare filtri impliciti e limitare i risultati restituiti solo al contenuto pertinente. Le Knowledge Base di Amazon Bedrock offrono modelli di reranker per migliorare la pertinenza dei blocchi di documenti recuperati.

Fornisci l'attribuzione delle origini
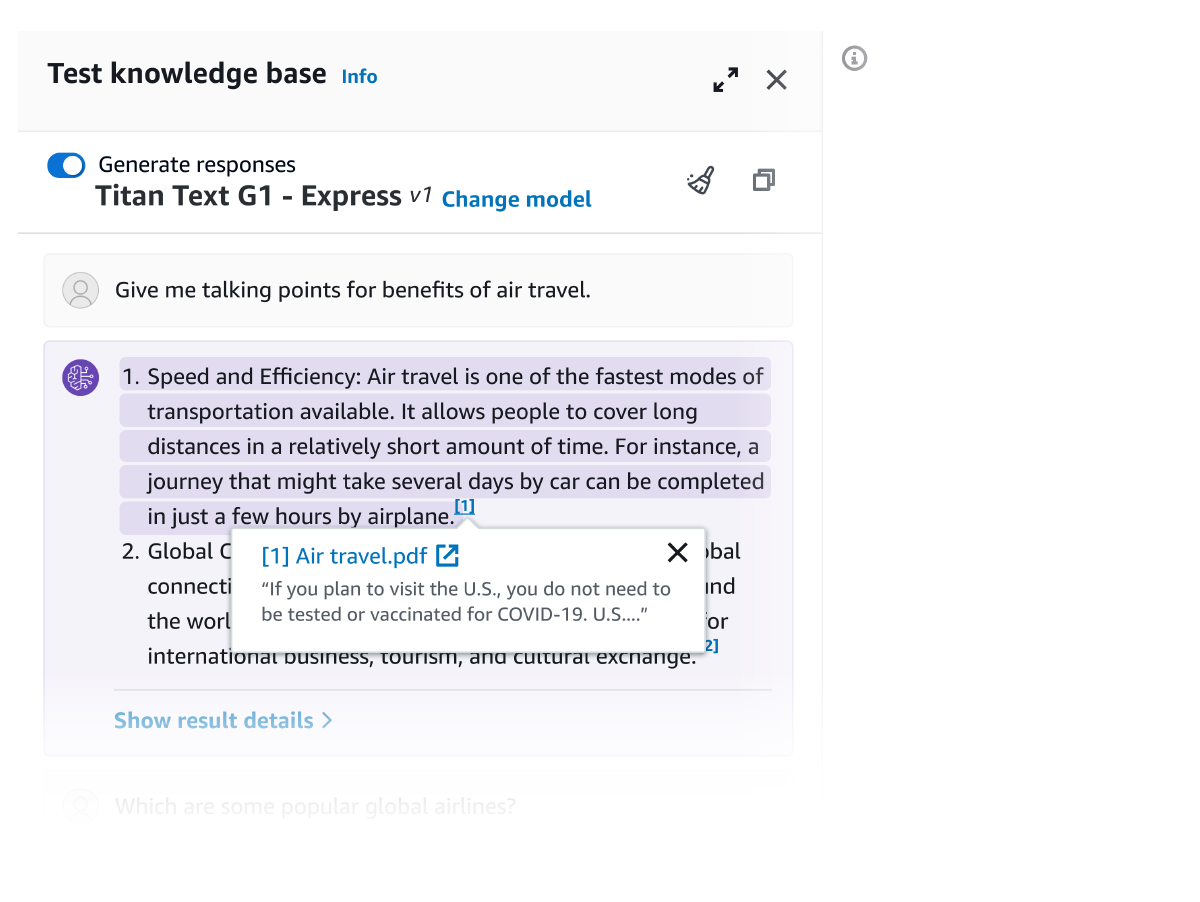
Tutte le informazioni recuperate dalle Knowledge Base di Amazon Bedrock vengono fornite con le rispettive citazioni (che includono anche immagini) per migliorare la trasparenza e ridurre al minimo le allucinazioni.
Come iniziare
Oggi hai trovato quello che cercavi?
Facci sapere la tua opinione in modo da poter migliorare la qualità dei contenuti delle nostre pagine.